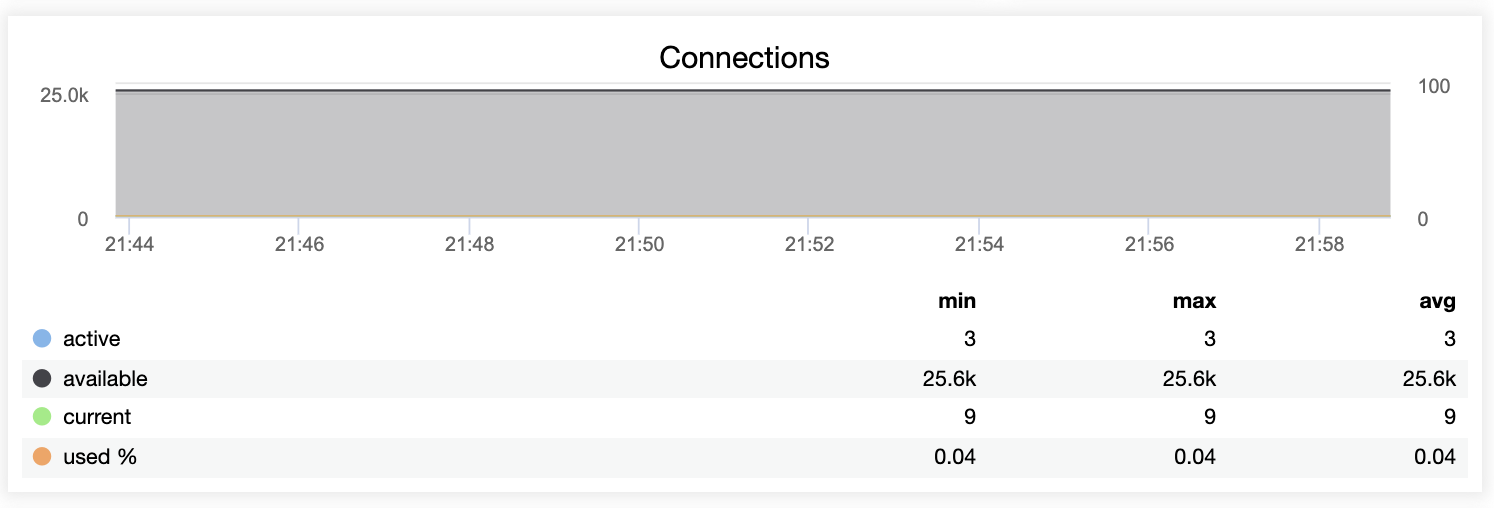
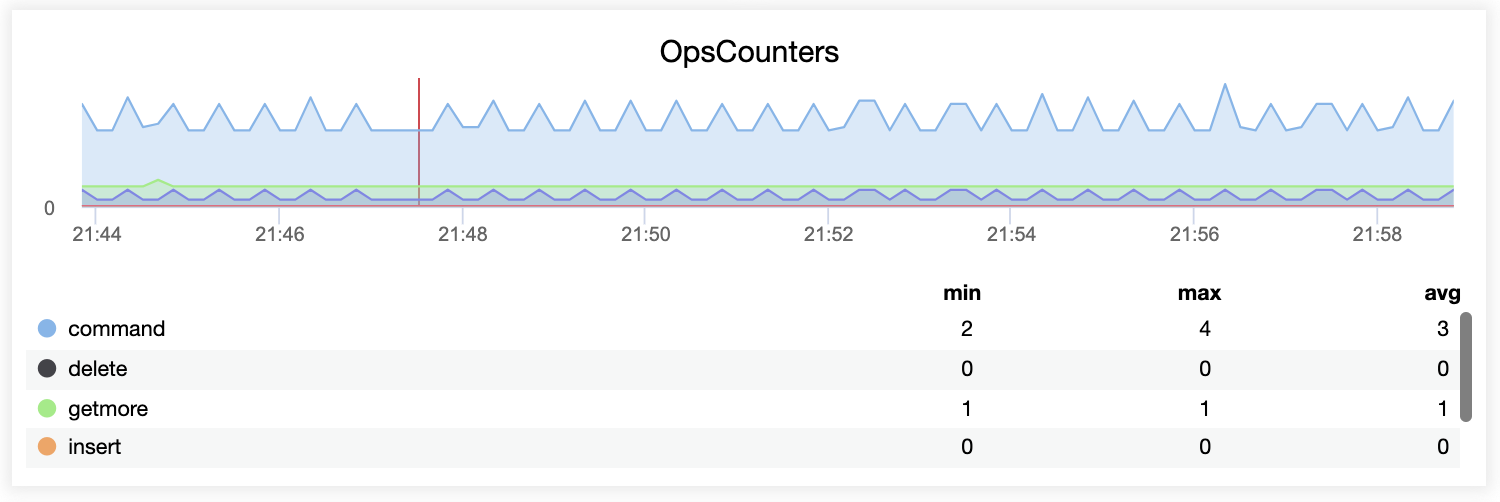
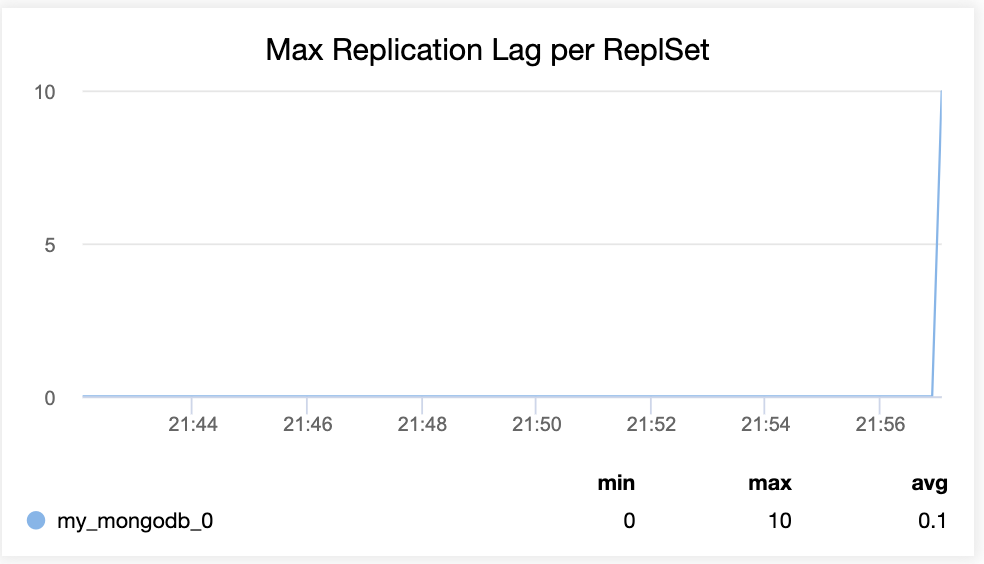
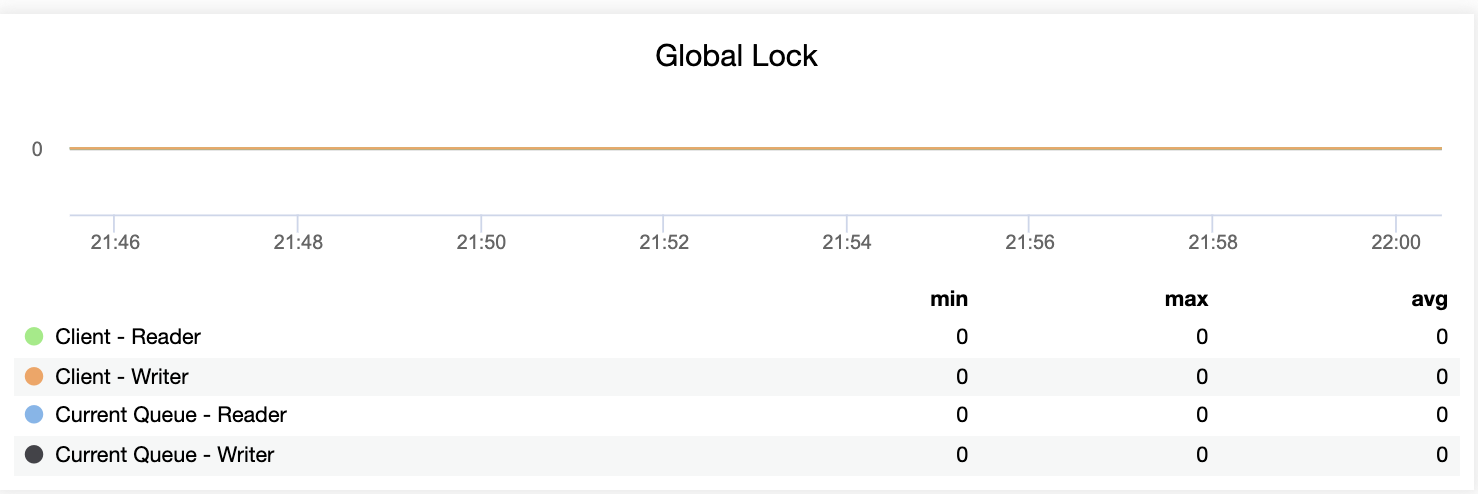
High availability is a must when you run critical services in your production environment. It can be achieved by eliminating all single points of failures, including the database tier. So you can imagine our surprise everytime we bump into setups with multiple web servers/applications all hitting one single database instance.
High availability service in MongoDB can be achieved through replication. The term replica set describes a setup where multiple MongoDB processes run and maintain the same data. In this blog, we will discuss how to deploy Percona Server for MongoDB to achieve high availability.
Deployment Percona Server for MongoDB
We need at least 3 nodes for high availability, a replica set will consist of 1 Primary node, and 2 Secondary nodes. You can use 2 nodes, 1 Primary and 1 Secondary, but you still need an arbiter as a third node. An arbiter is a MongoDB node which does not copy and store the data, but is involved in the election process of the new Primary when failover happens.
In this example, we are running 3 virtual environments with CentOS Linux release 7.3 as the operating system and will use Percona Server for MongoDB version 4.2 for the installation. The IP Address as below:
- mongo-node8: 10.10.10.17
- mongo-node9: 10.10.10.18
- mongo-node10: 10.10.10.19
Before we jump into the installation, please make sure that all nodes are already configured in /etc/hosts file on each node.
[root@mongo-node9 ~]# cat /etc/hosts
127.0.0.1 mongo-node9 mongo-node9
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.10.10.17 mongo-node8
10.10.10.18 mongo-node9
10.10.10.19 mongo-node10Then, we need to configure the Percona Repository on each of the nodes. After that, enable repository for psmdb42 as shown below:
[root@mongo-node8 ~]# percona-release setup psmdb42
* Disabling all Percona Repositories
* Enabling the Percona Server for MongoDB 4.2 repository
* Enabling the Percona Tools repository
<*> All done!And then continue install the Percona Server for MongoDB package :
[root@mongo-node8 ~]# yum install percona-server-mongodb*
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: centos.mirror.angkasa.id
* extras: centos.mirror.angkasa.id
* updates: centos.mirror.angkasa.id
Resolving Dependencies
--> Running transaction check
---> Package percona-server-mongodb.x86_64 0:4.2.9-10.el7 will be installed
--> Processing Dependency: cyrus-sasl-gssapi for package: percona-server-mongodb-4.2.9-10.el7.x86_64
--> Processing Dependency: numactl for package: percona-server-mongodb-4.2.9-10.el7.x86_64
---> Package percona-server-mongodb-debuginfo.x86_64 0:4.2.9-10.el7 will be installed
---> Package percona-server-mongodb-mongos.x86_64 0:4.2.9-10.el7 will be installed
--> Processing Dependency: libcrypto.so.10(OPENSSL_1.0.2)(64bit) for package: percona-server-mongodb-mongos-4.2.9-10.el7.x86_64
---> Package percona-server-mongodb-server.x86_64 0:4.2.9-10.el7 will be installed
---> Package percona-server-mongodb-shell.x86_64 0:4.2.9-10.el7 will be installed
---> Package percona-server-mongodb-tools.x86_64 0:4.2.9-10.el7 will be installed
--> Running transaction check
---> Package cyrus-sasl-gssapi.x86_64 0:2.1.26-23.el7 will be installed
--> Processing Dependency: cyrus-sasl-lib(x86-64) = 2.1.26-23.el7 for package: cyrus-sasl-gssapi-2.1.26-23.el7.x86_64
---> Package numactl.x86_64 0:2.0.12-5.el7 will be installed
---> Package openssl-libs.x86_64 1:1.0.1e-60.el7_3.1 will be updated
--> Processing Dependency: openssl-libs(x86-64) = 1:1.0.1e-60.el7_3.1 for package: 1:openssl-1.0.1e-60.el7_3.1.x86_64
---> Package openssl-libs.x86_64 1:1.0.2k-19.el7 will be an update
--> Running transaction check
---> Package cyrus-sasl-lib.x86_64 0:2.1.26-20.el7_2 will be updated
---> Package cyrus-sasl-lib.x86_64 0:2.1.26-23.el7 will be an update
---> Package openssl.x86_64 1:1.0.1e-60.el7_3.1 will be updated
---> Package openssl.x86_64 1:1.0.2k-19.el7 will be an update
--> Finished Dependency Resolution
Dependencies Resolved
================================================================
Package Arch Version Repository
Size
================================================================
Installing:
percona-server-mongodb x86_64 4.2.9-10.el7 psmdb-42-release-x86_64
4.9 k
percona-server-mongodb-debuginfo
x86_64 4.2.9-10.el7 psmdb-42-release-x86_64
885 M
percona-server-mongodb-mongos
x86_64 4.2.9-10.el7 psmdb-42-release-x86_64
10 M
percona-server-mongodb-server
x86_64 4.2.9-10.el7 psmdb-42-release-x86_64
22 M
percona-server-mongodb-shell x86_64 4.2.9-10.el7 psmdb-42-release-x86_64
12 M
percona-server-mongodb-tools x86_64 4.2.9-10.el7 psmdb-42-release-x86_64
30 M
Installing for dependencies:
cyrus-sasl-gssapi x86_64 2.1.26-23.el7 base 41 k
numactl x86_64 2.0.12-5.el7 base 66 k
Updating for dependencies:
cyrus-sasl-lib x86_64 2.1.26-23.el7 base 155 k
openssl x86_64 1:1.0.2k-19.el7 base 493 k
openssl-libs x86_64 1:1.0.2k-19.el7 base 1.2 M
Transaction Summary
================================================================
Install 6 Packages (+2 Dependent packages)
Upgrade ( 3 Dependent packages)
Total download size: 960 M
Is this ok [y/d/N]:
. . . .
Installed:
percona-server-mongodb.x86_64 0:4.2.9-10.el7
percona-server-mongodb-debuginfo.x86_64 0:4.2.9-10.el7
percona-server-mongodb-mongos.x86_64 0:4.2.9-10.el7
percona-server-mongodb-server.x86_64 0:4.2.9-10.el7
percona-server-mongodb-shell.x86_64 0:4.2.9-10.el7
percona-server-mongodb-tools.x86_64 0:4.2.9-10.el7
Dependency Installed:
cyrus-sasl-gssapi.x86_64 0:2.1.26-23.el7
numactl.x86_64 0:2.0.12-5.el7
Dependency Updated:
cyrus-sasl-lib.x86_64 0:2.1.26-23.el7
openssl.x86_64 1:1.0.2k-19.el7
openssl-libs.x86_64 1:1.0.2k-19.el7Repeat the installation on the other nodes. After installation completed, please change the bindIP configuration on /etc/mongod.conf from localhost IP Address to all of private IP Addresses as shown below:
# network interfaces
net:
port: 27017
bindIp: 0.0.0.0You can also restrict the IP Address on bindIP parameter for security reasons, just add the IP address with semicolon as a separator.
Ensure we can connect into MongoDB instance between the three nodes as shown below example:
[root@mongo-node8 ~]# mongo --host 10.10.10.19 --port 27017
Percona Server for MongoDB shell version v4.2.9-10
connecting to: mongodb://10.10.10.19:27017/?compressors=disabled&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("99afee8f-a194-4d0a-963a-6dfdc17f5bee") }
Percona Server for MongoDB server version: v4.2.9-10
Server has startup warnings:
2020-10-30T04:38:46.244+0000 I CONTROL [initandlisten]
2020-10-30T04:38:46.244+0000 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database.
2020-10-30T04:38:46.244+0000 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted.
2020-10-30T04:38:46.244+0000 I CONTROL [initandlisten] ** You can use percona-server-mongodb-enable-auth.sh to fix it.
2020-10-30T04:38:46.244+0000 I CONTROL [initandlisten]The next step is to configure replicaset in MongoDB. We need to edit the file /etc/mongod.conf and uncomment the replication section and add parameter replSetName as shown below:
replication:
replSetName: "my-mongodb-rs"We use the replicaset name my-mongodb-rs in this installation. After replication configuration is added, then restart the mongodb service.
$ service mongod restartRepeat the configuration on the other nodes.
Once done, we need to initialize the replication in one of the nodes. Connect to mongodb and run rs.initiate() command as shown below:
> rs.initiate()
{
"info2" : "no configuration specified. Using a default configuration for the set",
"me" : "mongo-node8:27017",
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1604036305, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1604036305, 1)
}
my-mongodb-rs:OTHER>
my-mongodb-rs:PRIMARY>As we can see in the nodes, the first node where we initiate the replication will become a PRIMARY node. We need to add the rest of the nodes to join the replication.
Add the other nodes usingrs.add() command on PRIMARY nodes as below:
my-mongodb-rs:PRIMARY> rs.add("mongo-node9:27017");
{
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1604037158, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1604037158, 1)
}
my-mongodb-rs:PRIMARY> rs.add("mongo-node10:27017");
{
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1604037170, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1604037170, 1)
}Another option to initiate the Replica Set using initiate() command is to pass the node’s IP address information for all nodes as shown below:
rs.initiate( {
_id: "my-mongodb-rs",
members: [
{ _id: 0, host: "mongo-node8:27017" },
{ _id: 1, host: "mongo-node9:27017" },
{ _id: 2, host: "mongo-node10:27017" }
] })We can check the current replica set cluster using rs.status() command on any cluster nodes:
my-mongodb-rs:PRIMARY> rs.status()
{
"set" : "my-mongodb-rs",
"date" : ISODate("2020-10-30T06:27:41.693Z"),
"myState" : 1,
"term" : NumberLong(1),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"heartbeatIntervalMillis" : NumberLong(2000),
"majorityVoteCount" : 2,
"writeMajorityCount" : 2,
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1604039248, 1),
"t" : NumberLong(1)
},
"lastCommittedWallTime" : ISODate("2020-10-30T06:27:28.305Z"),
"readConcernMajorityOpTime" : {
"ts" : Timestamp(1604039248, 1),
"t" : NumberLong(1)
},
"readConcernMajorityWallTime" : ISODate("2020-10-30T06:27:28.305Z"),
"appliedOpTime" : {
"ts" : Timestamp(1604039248, 1),
"t" : NumberLong(1)
},
"durableOpTime" : {
"ts" : Timestamp(1604039248, 1),
"t" : NumberLong(1)
},
"lastAppliedWallTime" : ISODate("2020-10-30T06:27:28.305Z"),
"lastDurableWallTime" : ISODate("2020-10-30T06:27:28.305Z")
},
"lastStableRecoveryTimestamp" : Timestamp(1604039245, 1),
"lastStableCheckpointTimestamp" : Timestamp(1604039245, 1),
"electionCandidateMetrics" : {
"lastElectionReason" : "electionTimeout",
"lastElectionDate" : ISODate("2020-10-30T05:38:25.155Z"),
"electionTerm" : NumberLong(1),
"lastCommittedOpTimeAtElection" : {
"ts" : Timestamp(0, 0),
"t" : NumberLong(-1)
},
"lastSeenOpTimeAtElection" : {
"ts" : Timestamp(1604036305, 1),
"t" : NumberLong(-1)
},
"numVotesNeeded" : 1,
"priorityAtElection" : 1,
"electionTimeoutMillis" : NumberLong(10000),
"newTermStartDate" : ISODate("2020-10-30T05:38:25.171Z"),
"wMajorityWriteAvailabilityDate" : ISODate("2020-10-30T05:38:25.180Z")
},
"members" : [
{
"_id" : 0,
"name" : "mongo-node8:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 3014,
"optime" : {
"ts" : Timestamp(1604039248, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2020-10-30T06:27:28Z"),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"infoMessage" : "",
"electionTime" : Timestamp(1604036305, 2),
"electionDate" : ISODate("2020-10-30T05:38:25Z"),
"configVersion" : 7,
"self" : true,
"lastHeartbeatMessage" : ""
},
{
"_id" : 1,
"name" : "mongo-node9:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 226,
"optime" : {
"ts" : Timestamp(1604039248, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1604039248, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2020-10-30T06:27:28Z"),
"optimeDurableDate" : ISODate("2020-10-30T06:27:28Z"),
"lastHeartbeat" : ISODate("2020-10-30T06:27:40.520Z"),
"lastHeartbeatRecv" : ISODate("2020-10-30T06:27:40.519Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "",
"syncingTo" : "mongo-node8:27017",
"syncSourceHost" : "mongo-node8:27017",
"syncSourceId" : 0,
"infoMessage" : "",
"configVersion" : 7
},
{
"_id" : 2,
"name" : "mongo-node10:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 201,
"optime" : {
"ts" : Timestamp(1604039248, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1604039248, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2020-10-30T06:27:28Z"),
"optimeDurableDate" : ISODate("2020-10-30T06:27:28Z"),
"lastHeartbeat" : ISODate("2020-10-30T06:27:40.520Z"),
"lastHeartbeatRecv" : ISODate("2020-10-30T06:27:40.688Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "",
"syncingTo" : "mongo-node8:27017",
"syncSourceHost" : "mongo-node8:27017",
"syncSourceId" : 0,
"infoMessage" : "",
"configVersion" : 7
}
],
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1604039248, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1604039248, 1)
}Deploy Percona Server for MongoDB using ClusterControl
ClusterControl supports deployment for Percona Server for MongoDB. Versions supported include 3.4, 3.6, 4.0, and 4.2. The deployment is straightforward, you just need to go to Deploy, and choose the MongoDB Replicaset tab as shown below:

Fill in the SSH user, password, port and the cluster name. ClusterControl requires you to set up passwordless SSH between the controller node and target database node before installation. After all information is filled in, click Continue. There will be another page as shown below:

Choose Percona as a Vendor, select the Version you want to install. If you have a custom MongoDB data directory, you need to specify it. Set admin user and password for your MongoDB. If you want to use another port instead of using default (re. 27017), you can change it to another port number. Last step is to fill the IP address of your target database node in the Add Node combo box.
After all is finished, just click the Deploy button. It will trigger a job to deploy a MongoDB cluster as shown below:

After deployment is done, you can see the Overview page that you already have 3 instances of Percona Server for MongoDB that are up and running.

The Topology View below shows that you have 1 Primary and 2 Secondary nodes: